GenAI - L’Abstention Calibrée.

Quand le refus devient une compétence stratégique
Au premier trimestre 2026, les tribunaux américains ont prononcé au moins 145 000 dollars de sanctions liées à des hallucinations générées par IA dans des mémoires judiciaires (Source : JD Supra – The AI Sanction Wave: $145K in Q1 Penalties).
Cela n'est pas un incident isolé et révèle une limite structurelle des modèles actuels : une tendance à produire une réponse même en situation d’incertitude élevée. Aujourd'hui, la maturité d’un système d’IA ne se mesure pas qu'à sa capacité de réponse, mais également à sa capacité d’abstention calibrée et vérifiable.
Cette approche, l’abstention calibrée, transforme le silence en décision auditable. Le terme s'inscrit dans une généalogie académique articulée en trois étapes. Les fondations théoriques remontent aux travaux de Hendrycks & Gimpel qui établissent dès 2017 que la distribution de confiance d'un réseau de neurones permet de détecter les prédictions susceptibles d'être erronées ou hors distribution, posant ainsi le premier fondement technique d'un mécanisme d'abstention par score d'incertitude (A Baseline for Detecting Misclassified and Out-of-Distribution Examples in Neural Networks). Geifman & El-Yaniv formalisent ensuite la selective prediction : un classifieur peut, à l'inférence, rejeter les instances incertaines de façon à garantir un niveau de risque cible avec une probabilité arbitrairement élevée (Selective Classification for Deep Neural Networks). Ces fondements sont transposés aux grands modèles de langage par Tomani et al. (Meta + Technical University of Munich, 2024), qui démontrent empiriquement que l'abstention pilotée par l'incertitude améliore simultanément la correction, la réduction des hallucinations et la sécurité des LLMs (Uncertainty-Based Abstention in LLMs Improves Safety and Reduces Hallucinations).
Le coût mesurable d’une réponse systématique
Depuis 2022, les grands modèles ont été optimisés prioritairement pour la « helpfulness ». Ce biais de production a un prix désormais quantifiable.
Sur le plan juridique, les outils spécialisés affichent des taux d’hallucinations documentés à plus de 17 % pour Lexis+ AI et environ 33 % pour Westlaw AI-Assisted Research sur des requêtes réalistes (étude comparative Stanford HAI / RegLab). (Source : Magesh et al., « Hallucination-Free? Assessing the Reliability of Leading AI Legal Research Tools », Journal of Empirical Legal Studies, 2025 ; HAI News). Ces erreurs se traduisent par des sanctions allant de plusieurs milliers à plus de 100 000 dollars par affaire.
Le cadre réglementaire européen renforce cette exigence. L'AI Act impose un système de gestion des risques continu tout au long du cycle de vie des systèmes à haut risque. Les Articles 12 (tenue de logs techniques) et 13 (transparence vis-à-vis des deployers) exigent traçabilité et information claire sur les capacités et limites du système. L’abstention calibrée constitue une mesure technique défendable pour contribuer à la mitigation des risques et à la démonstration de conformité, sans être la seule voie possible.(Source : EU AI Act – Article 9, Article 12, Article 13). Trois instruments complémentaires renforcent cette exigence opérationnelle au-delà du seul règlement. Le GPAI Code of Practice précise les obligations de transparence, de copyright et de gestion des risques systémiques pour les fournisseurs de modèles GPAI (texte officiel). La norme ISO/IEC 42001:2023 (AI Management System) fournit en parallèle un cadre de management certifiable, mobilisable par les CISO et DPO pour structurer la gouvernance interne autour de la traçabilité, de la maîtrise des risques et de la supervision humaine. Enfin, le RGPD se croise sur deux dimensions clés : l'article 22 (protection contre les décisions entièrement automatisées) et le principe de minimisation de l'article 5. L'abstention calibrée vérifiable s'inscrit ainsi à l'intersection de trois régimes, sectoriel (AI Act), management (ISO/IEC 42001), protection des données (RGPD), qui se renforcent.
La dette énergétique pèse lourdement sur la trajectoire. EPRI relève ses projections : les data centers pourraient consommer entre 9 % et 17 % de la production électrique américaine d'ici 2030, soit une révision d'environ +60 % par rapport à l'estimation initiale de mai 2024 (qui plafonnait à 9 %). À titre de comparaison, leur part actuelle se situe autour de 4-5 %. Les requêtes IA nécessitent environ dix fois plus d'électricité qu'une recherche internet classique, et les usages génératifs avancés (musique, images, vidéos) en requièrent davantage encore. La concentration des infrastructures amplifie la pression locale : un data center majeur peut désormais demander une puissance équivalente à celle de 80 000 à 800 000 foyers. Les modèles de raisonnement avancés, plus gourmands en compute, accentuent cette trajectoire. (Sources : EPRI Powering Intelligence 2024 ; EPRI Powering Intelligence – Updated U.S. Scenarios, 2026)
Enfin, la dette de confiance est mesurable. Le Flash Poll Edelman Trust and Artificial Intelligence at a Crossroads (5 000 répondants, 5 marchés) documente une fracture géographique : la confiance dans l'IA atteint 87 % en Chine et 67 % au Brésil, contre seulement 39 % en Allemagne, 36 % au Royaume-Uni et 32 % aux États-Unis, ces trois marchés restant en défiance. Aux États-Unis, cette stagnation à bas niveau (+2 points seulement depuis novembre 2023) masque une résistance active : les Américains sont plus de deux fois plus nombreux à rejeter l'IA qu'à l'embrasser (49 % contre 17 %). La source du blocage est identifiée : 70 % des utilisateurs peu fréquents aux États-Unis citent les problèmes de confiance comme premier frein, largement devant le manque d'intérêt (31 %) ou la difficulté d'accès (16 %). Parmi ces obstacles de confiance, la préoccupation sur l'exactitude des réponses est centrale : 59 % des répondants américains déclarent qu'une plus grande transparence des plateformes IA sur les imprécisions potentielles de leurs réponses augmenterait leur enthousiasme à adopter la technologie. L'abstention calibrée le rend possible : transformer l'incertitude en signal explicite plutôt qu'en erreur silencieuse (Source : Trust and Artificial Intelligence at a Crossroads).
L’abstention calibrée comme levier de fiabilité
L’abstention calibrée repose sur un principe opérationnel clair : ne pas répondre devient la sortie par défaut dès que l’incertitude mesurée dépasse un seuil défini et justifié.
Elle ne constitue pas une idée entièrement nouvelle : les fondements théoriques de l’abstention calibrée existent dans la littérature scientifique depuis 2017. Des travaux sur la sélection prédictive, la prédiction conforme et l’abstention dans les questions à choix multiples (abstention in MCQA) remontent au moins à 2017 (Geifman & El-Yaniv, NeurIPS 2017 ; arXiv:1705.08500). Aujourd'hui, la convergence de trois facteurs nouveaux: (i) des modèles suffisamment grands pour que l'abstention mal calibrée devienne un risque légal chiffré, (ii) des outils de calibration statistique matures et accessibles (comme MAPIE), et (iii) un cadre réglementaire (EU AI Act) qui transforme la traçabilité de l'incertitude en obligation. Cette convergence constitue un point d’inflexion opérationnel et réglementaire en 2026.
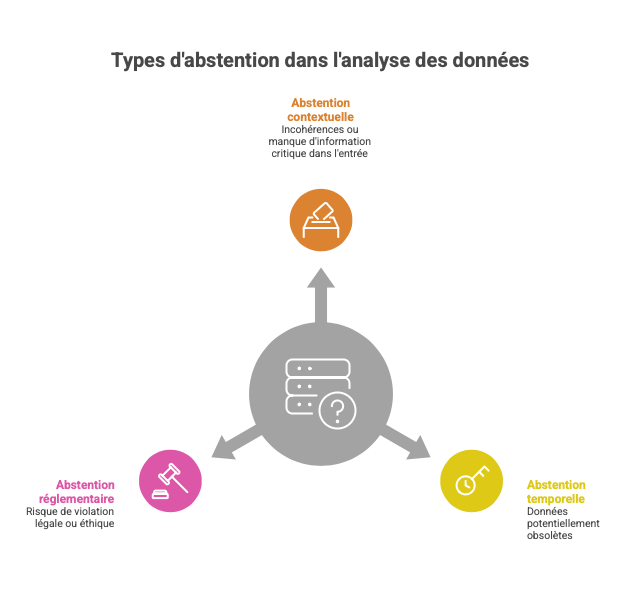
Trois formes principales sont identifiées :
- Abstention contextuelle : incohérences ou manque d’information critique dans l’entrée.
- Abstention temporelle : données potentiellement obsolètes.
- Abstention réglementaire ou éthique : risque de violation légale ou inacceptable.
Des travaux récents confirment la maturité de ces mécanismes :
- Abstain-R1 propose un reinforcement learning with verifiable reward (RLVR) qui optimise à la fois l’abstention et la clarification post-refus sur des requêtes non répondables, tout en préservant la performance sur les requêtes répondables (modèle 3B compétitif avec des systèmes plus grands). (Source : arXiv:2604.17073).
- MedAbstain est un benchmark unifié pour l’abstention en MCQA médical, combinant conformal prediction, perturbations adverses et options d’abstention explicites. Il démontre que même les modèles à haute précision échouent souvent à s’abstenir quand l’incertitude clinique est élevée. (Source : arXiv:2601.12471).
- AbstentionBench confirme que le reasoning fine-tuning dégrade même l’abstention de 24 % en moyenne sur des questions non répondables. (Source : Kirichenko et al., arXiv:2506.09038 ; NeurIPS 2025 Poster).
Le différenciateur clé : la preuve d’abstention vérifiable
L’avancée ne réside pas dans le refus lui-même, mais dans sa preuve technique.
L’architecture repose sur un système dual :
- Un modèle principal propose une réponse.
- Un module auxiliaire qui mesure la cohérence interne du modèle analyse des signaux internes (entropie des logits, variance, stabilité inter-couches).
La conformal prediction (librairie MAPIE) fournit des garanties statistiques distribution-free. Ces décisions d’abstention peuvent ensuite être attestées par des protocoles cryptographiques : zk-SNARKs ou équivalents (Source : zkLLM – arXiv:2404.16109).
Ce mécanisme répond aux exigences des Articles 9, 12 et 13 de l’EU AI Act en transformant les obligations documentaires en fonctionnalités auditables.
La preuve cryptographique reste, en 2026, plus adaptée à un usage asynchrone ou audit que temps-réel pour les modèles les plus lourds.
L'abstention calibrée : condition nécessaire, non suffisante
L'abstention calibrée résout un problème précis et documenté : la tendance des modèles à produire une réponse même en situation d'incertitude élevée. Mais réduire la fiabilité d'un système IA à ce seul mécanisme serait une erreur de cadrage.
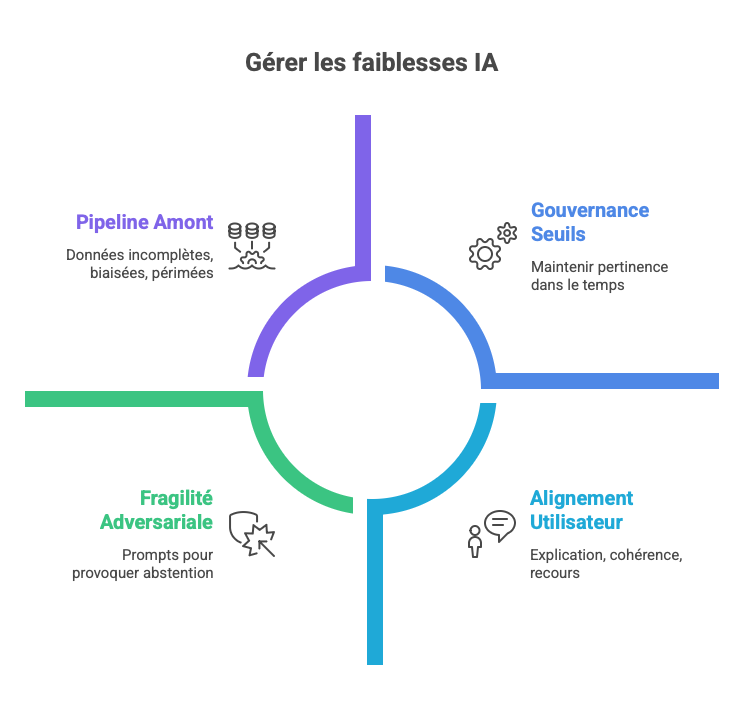
Quatre lacunes subsistent en dehors du périmètre de l'abstention.
-
La première est la qualité du pipeline amont. Un modèle calibré pour s'abstenir reste vulnérable si les données qui l'alimentent sont incomplètes, biaisées ou périmées. L'abstention ne corrige pas une base de connaissance défaillante ; elle peut signaler qu'elle ne sait pas répondre avec ce qu'on lui a donné. La gestion des sources, la fraîcheur des données et la qualité du retrieval dans les architectures RAG restent des prérequis indépendants.
-
La seconde est la gouvernance des seuils dans la durée. Calibrer un seuil d'abstention au moment du déploiement est un acte technique ponctuel. Le maintenir pertinent dans le temps, face à l'évolution des cas d'usage, des distributions de requêtes, et des exigences réglementaires, suppose une fonction dédiée, des processus de révision périodique et une responsabilité attribuée. Sans cette infrastructure organisationnelle, le seuil se dégrade, et l'audit devient impossible. L'EU AI Act (Article 9) impose cette continuité : la gestion des risques est un système, pas un paramètre.
-
La troisième est l'alignement utilisateur. Un système qui s'abstient de manière opaque ou trop fréquente génère un contournement : les utilisateurs apprennent à reformuler leurs requêtes pour forcer une réponse, annulant le bénéfice de sécurité. La confiance ne se décrète pas par le refus ; elle se construit par la qualité de l'explication fournie lors de l'abstention, par la cohérence du comportement dans le temps, et par un mécanisme de recours transparent lorsque l'abstention est jugée injustifiée.
-
La quatrième fragilité est adversariale. Un système d'abstention calibrée ouvre une nouvelle surface d'attaque : un attaquant peut concevoir des prompts pour faire artificiellement franchir le seuil d'incertitude, provoquant un déni de service par abstention massive ; ou inversement déprimer le score de confiance interne tout en obtenant une réponse erronée (uncertainty manipulation). La littérature documente déjà ce risque sous l'angle du calibration drift sous distribution shift, et du contournement des estimateurs d'incertitude. Toute architecture en production doit intégrer (i) un monitoring continu de la distribution des seuils déclenchés, (ii) un red-teaming dédié à l'attaque du module d'abstention, et (iii) une politique de revue humaine pour les cas où l'abstention elle-même devient suspecte (taux anormaux, patterns adversariaux détectés). Ces obligations se rattachent directement à l'article 9 de l'AI Act sur la gestion continue des risques tout au long du cycle de vie.
L'abstention calibrée est donc la pièce centrale d'un système de confiance. Elle prend toute sa valeur lorsqu'elle s'articule avec une gouvernance des données rigoureuse, une fonction IA fiabilité transverse, et une expérience utilisateur conçue pour transformer le refus en signal utile plutôt qu'en friction. À cette condition, elle tient sa promesse : rendre la confiance de l'IA mesurable. D’autres techniques complémentaires restent indispensables : évaluation de la faithfulness dans les architectures RAG, self-consistency, process supervision, et supervision humaine renforcée (Art. 14).
Cas d’usage et gains concrets
Un exemple souvent cité pour illustrer l'abstention par contrainte éditoriale : AskVera, service opéré par l'ONG LaReponse.Tech, qui restreint ses sources à une liste blanche d'environ 300-400 sources sélectionnées dans 80 pays — environ 100 fact-checkers certifiés IFCN/EFCSN, complétés par 200 médias éditoriaux de référence. La philosophie affichée est proche de l'abstention calibrée : « Vera ne devine jamais. Si une information est invérifiable, elle l'indiquera clairement. » Ce cas mérite cependant une lecture critique. La sécurisation des sources d'un RAG ne résout qu'une moitié du problème : la qualité de la récupération (retrieval). Elle ne garantit en rien la fidélité de la génération (faithfulness). Un modèle peut parfaitement récupérer un document certifié et en produire une synthèse inexacte — par troncature, recombinaison erronée de passages, ou inférence non supportée par le texte source. Ce phénomène, la faithfulness hallucination, est distinct de l'hallucination factuelle classique et documenté dans les benchmarks RAG spécialisés (RAGAS, Es et al., 2023, arXiv:2309.15217 ; Benchmarking Large Language Models in Retrieval-Augmented Generation, Chen et al., 2024, arXiv:2309.01431). AskVera illustre donc une condition nécessaire de l'abstention calibrée mais non suffisante. Une abstention fiable exige un scoring d'incertitude appliqué aussi à la phase de génération : mesure de la cohérence entre le passage récupéré et la réponse produite, détection des tokens générés sans ancrage dans le contexte (grounding score), et idéalement un mécanisme de vérification post-génération source-à-sortie. Sans cette couche, la liste blanche de sources crée une illusion de sécurité plus qu'une garantie. (Source : AskVera.org – FAQ et fonctionnement).
Plusieurs approches industrielles convergent partiellement vers ces principes. Les architectures modernes de RAG avec citations granulaires (au niveau du token ou du passage) rendent traçable l'ancrage de chaque assertion ; certains éditeurs documentent publiquement leur positionnement sur l'honnêteté épistémique et la préférence pour l'expression d'incertitude plutôt que la fabrication. Dans les domaines verticaux à fort enjeu (juridique, santé), des seuils explicites de refus avec escalade humaine commencent à être implémentés. Aucune de ces approches ne constitue à ce jour une abstention calibrée vérifiable au sens cryptographique complet, mais elles dessinent la trajectoire industrielle pour les 18-24 prochains mois et permettent de tester en production les composantes du dispositif (mesure d'incertitude, seuils, journalisation auditée)
Une étude KPMG Global AI Trust 2025 indique que la transparence sur l’incertitude augmente la confiance utilisateur de manière significative. (Source : KPMG – Trust, attitudes and use of artificial intelligence: A global study 2025). L'argument économique est documenté par deux sources convergentes. Thomson Reuters, dans son rapport Future of Professionals 2025 (juin 2025), établit que les organisations dotées d'une stratégie IA explicite sont deux fois plus susceptibles d'enregistrer une croissance de revenus portée par l'IA que celles qui adoptent l'IA de manière informelle (Thomson Reuters – Future of Professionals Report 2025). BCG affine ce constat dans son étude The Widening AI Value Gap (septembre 2025, enquête menée auprès de 1 250 dirigeants et décideurs IA dans 9 industries). Les entreprises dites « future-built » affichent une maturité 5× supérieure en gouvernance et garde-fous IA responsables. Cette gouvernance se traduit en performance financière : 1,7× de croissance de revenus, 1,6× de marge EBIT, et un retour total pour l'actionnaire (TSR) 3,6× plus élevé sur trois ans. Dans les périmètres où l'IA est déployée, ces entreprises capturent un doublement des gains de revenus et 40 % de réduction de coûts supplémentaires par rapport aux retardataires. La gouvernance responsable est ainsi un levier de performance, plutôt qu'un coût de conformité subi. (BCG – Are You Generating Value from AI? The Widening Gap, 2025)
Note sur la portée : ces gains sont marqués dans les domaines high-stakes (droit, santé, finance). Pour les usages créatifs ou conversationnels à faible enjeu, une abstention « douce » (clarification ou suggestion de reformulation) peut être préférable à un refus total, afin de préserver l’expérience utilisateur sans compromettre la fiabilité.
Mise en œuvre pratique
La stack technologique mature en 2026 repose sur trois briques open-source ou disponibles :
-
Reinforcement Learning with Refusal Feedback / Verifiable RL : Abstain-R1 (Zhai et al., 2026) démontre qu’un reward clarification-aware permet d’entraîner un modèle 3B à s’abstenir et clarifier de façon vérifiable, sans dégrader la performance sur les questions répondables. Frameworks : RLVR ou R-Tuning. (Source : arXiv:2604.17073).
-
Conformal Prediction : la conformal prediction permet de quantifier l'incertitude distribution-free sur les LLMs (y compris en black-box via wrapping post-hoc), avec des garanties statistiques formelles sur le taux d'erreur. La librairie MAPIE (scikit-learn-contrib) en est l'une des implémentations open source de référence ; sa roadmap 2026 cible explicitement les cas d'usage LLM (LLM-as-Judge, segmentation, tests d'échangeabilité), même si l'intégration directe sur LLMs reste à ce jour assurée principalement via des wrappers post-hoc (cf. travaux Capgemini Invent Lab, juin 2025). Plusieurs benchmarks récents, dont MedAbstain pour le domaine médical, combinent conformal prediction et perturbations adversariales pour évaluer la qualité d'abstention.
-
Couche cryptographique légère : zkLLM propose un système de preuves à divulgation nulle de connaissance (zero-knowledge proofs) appliqué aux grands modèles de langage : il permet de prouver cryptographiquement qu'une inférence a bien été réalisée par un modèle donné, sans révéler les paramètres de ce modèle (qui restent protégés comme propriété intellectuelle) (Source : zkLLM arXiv).
Délai et ressources réalistes : un proof-of-concept production-ready (calibration des seuils sur données représentatives, benchmarks AbstentionBench/MedAbstain, audit cryptographique partiel) demande typiquement 4 à 6 mois pour une équipe de 3 à 5 ingénieurs ML/MLOps expérimentés. L'investissement total se situe à titre indicatif entre 400 k€ et 800 k€ tout compris (équipe, compute de calibration et d'évaluation, audit externe), ces fourchettes restant ouvertes en l'absence de benchmark public consolidé. Le retour sur investissement se mesure dans deux directions : réduction du coût des hallucinations en production (sanctions, retraitements, perte de confiance utilisateur) et accélération du cycle d'audit pour les obligations AI Act, GPAI Code of Practice et ISO/IEC 42001.
Défis et mitigations :
- Latence et coût : la génération d'une preuve zk-SNARK sur une inférence LLM reste coûteuse, mais l'état de l'art progresse vite. zkGPT (Qu et al., USENIX Security 2025) atteint moins de 25 secondes pour prouver une inférence GPT-2, soit environ 279× plus rapide que l'état de l'art précédent. zkLLM (Sun et al., CCS 2024, arXiv:2404.16109) rapporte quant à lui des preuves sous 15 minutes pour des modèles de 13 milliards de paramètres (OPT, LLaMa-2). Ces ordres de grandeur restent rédhibitoires pour une application temps-réel sans optimisation supplémentaire.. Deux stratégies de mitigation existent : (1) preuve asynchrone, la décision d'abstention est prise en temps-réel, la preuve cryptographique est générée en différé et archivée pour audit ultérieur, ce qui est suffisant pour la plupart des exigences réglementaires ; (2) preuve partielle, on prouve uniquement le dépassement du seuil sur les tokens-clés, pas l'inférence complète, réduisant le coût de calcul d'un ordre de grandeur. Dans les cas critiques temps-réel (trading algorithmique, triage d'urgence), la preuve asynchrone est la voie réaliste à court terme.
- Calibration des seuils : le choix du seuil reste un art. MAPIE 2026 propose des outils de validation croisée et de contrôle de risque pour minimiser les abstentions excessives ou insuffisantes.
- Portée : Idéal pour les usages critiques ; pour les contextes conversationnels, combiner avec des mécanismes de clarification pour éviter une frustration perçue.
Objections et réponses factuelles
« Les utilisateurs vont être frustrés par les refus. »
Les méta-analyses 2025 (Edelman, KPMG) montrent que la transparence sur l’incertitude renforce la confiance à long terme. Un refus clair et expliqué (« Je ne dispose pas d’éléments suffisants pour répondre avec une fiabilité > 90 % ») est souvent mieux perçu qu’une réponse plausible mais erronée (exemple AskVera). Dans les usages grand public, une abstention « douce » (proposition de reformulation) atténue ce risque.
« On perd en puissance perçue. »
Une analyse BCG publiée en 2025 sur la création de valeur par l'IA indique que les entreprises qui priorisent la fiabilité et la gouvernance de leurs systèmes enregistrent des retours économiques supérieurs à leurs pairs, sans que le rapport cite un ratio unique applicable à tous les secteurs (BCG – Are You Generating Value from AI? The Widening Gap, 2025). La logique est intuitive : chaque hallucination non interceptée dans un contexte critique (procédure judiciaire, prescription médicale) génère un coût correctif qui annule plusieurs dizaines d'inférences utiles. La valeur perçue passe de la quantité à la qualité et à la confiance.
Conclusion : optimiser par soustraction
Pendant une décennie, le progrès en IA s'est mesuré par accumulation : plus de paramètres, plus de données, plus de réponses générées. Ce paradigme arrive à sa limite. Les sanctions judiciaires américaines de Q1 2026, les taux d'hallucinations documentés sur les outils spécialisés et la défiance utilisateur structurelle dans les marchés développés convergent vers le même verdict : produire systématiquement une réponse n'est plus une preuve de capacité, c'est devenu un signe d'immaturité.
L'abstention calibrée propose une réponse ciblée à ce constat. Elle ajoute aux modèles une capacité qu'ils n'ont pas par défaut : signaler de manière auditée les zones où la fiabilité descend sous un seuil acceptable. Pour les domaines à enjeux (droit, santé, finance, conformité), cette capacité passe progressivement du registre du nice-to-have à celui de l'exigence réglementaire et contractuelle.
L'avantage compétitif se déplace en conséquence. Il ne suffira plus de produire une réponse juste : il faudra aussi pouvoir prouver, de manière vérifiable, que le système connaît les limites de sa propre confiance. Cette évolution est technique (incertitude calibrée, preuves cryptographiques), juridique (Articles 9, 12, 13, 14 de l'AI Act, GPAI Code of Practice, ISO/IEC 42001), et organisationnelle (gouvernance des seuils, monitoring continu, red-teaming spécifique). Elle rend l'IA opérable dans des contextes où l'erreur silencieuse n'est plus tolérable.
Lego VIII - sac 1 - Substractive strategy
Les opinions exprimées dans cet article sont strictement personnelles et ne reflètent pas nécessairement celles de mon employeur. Les contenus sont fournis à titre informatif et ne constituent pas un conseil juridique. Cet article explore des concepts architecturaux émergents et analyse des tendances de marché.