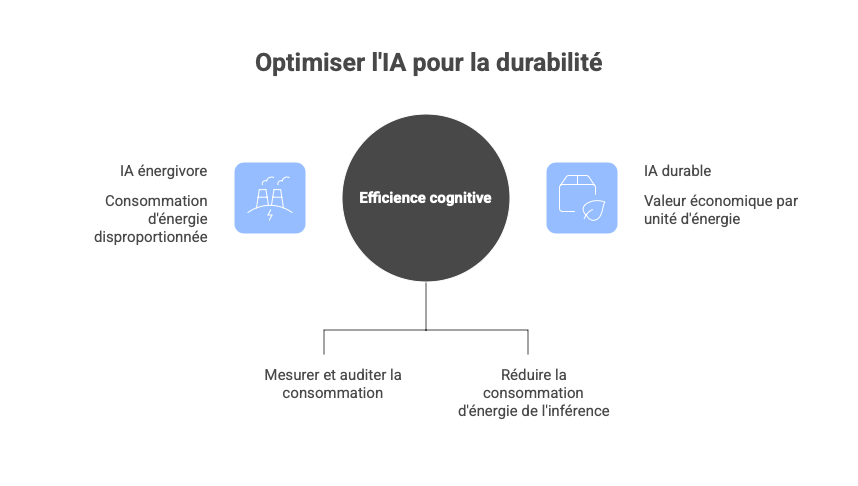
L'Efficience Cognitive

Le mur de verre de l’IA industrielle
L’intelligence artificielle est souvent évaluée sur sa précision, sa latence ou sa capacité à raisonner de manière complexe. Aujourd'hui les inquiétudes sur l'empreinte écologique mènent à des réflexions sur son rendement cognitif : la quantité de valeur business ou décisionnelle produite par unité d’énergie consommée, mesurée en kWh ou en tokens inférés par watt-heure.
Dès lors, un modèle qui excelle en benchmarks mais qui consomme de manière disproportionnée n’est plus un atout stratégique. Il représente un passif financier croissant, un risque de non-conformité au titre de la Corporate Sustainability Reporting Directive (CSRD), et un frein structurel à la scalabilité des agents autonomes, des workflows multi-agents et des applications industrielles à haute volumétrie.
Ce septième volet de la série prolonge directement la maîtrise en temps réel de l’action. Après avoir appris à borner, révoquer et overrider les délégations en temps réel pour préserver l’imputabilité causale et la résilience juridique, il faut maintenant borner leur coût énergétique de manière opposable, continue et auditable. L’efficience cognitive n’est pas une surcouche ESG cosmétique ou une bonne pratique volontaire ; c’est une propriété runtime indispensable à la viabilité économique, assurantielle et réglementaire de l’autonomie IA dans l’Europe soucieuse de son empreinte carbone.
Les projections convergent : la consommation électrique des data centers, déjà estimée à environ 415 TWh en 2024 (soit ~1,5 % de la consommation mondiale d’électricité), devrait doubler pour atteindre autour de 945 TWh d’ici 2030 dans le scénario de base de l’Agence Internationale de l’Énergie (IEA), avec l’IA comme principal moteur de croissance. En 2026, les estimations pointent vers plus de 500 TWh globalement, soit environ 2 % de la demande mondiale. L’inférence, et non plus l’entraînement, domine désormais : elle représente 70–90 % de la consommation énergétique totale du cycle de vie des LLM dans de nombreux cas d’usage production. ( IEA, Deloitte, technologicalreview )
Ce basculement transforme l’unité de compte de la valeur économique de l’IA : le ratio valeur/KWh s'ajoute à la précision ou la vitesse.
La tenaille réglementaire : CSRD, AI Act et convergence émergente
CSRD & ESRS E1 (Climate Change)
La CSRD impose de matérialiser l’impact de l’entreprise sur le climat (y compris via les émissions indirectes pour les services informatiques, API, inférence externalisée et modèles acquis) et l’impact du coût énergétique et des risques climatiques sur la viabilité économique de l’entreprise.
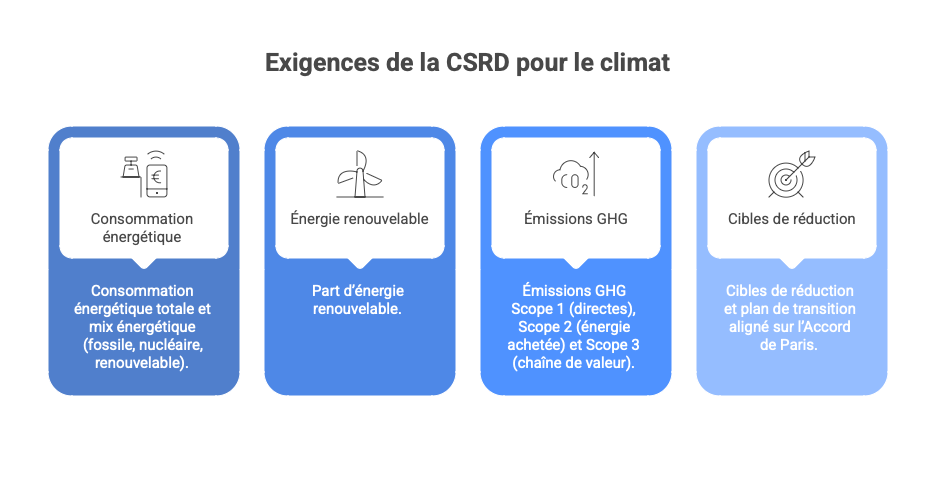
ESRS E1 (le standard européen de reporting sur la durabilité intitulé "Climate Change") exige de fournir des informations sur :
- la consommation énergétique totale et le mix énergétique (fossile, nucléaire, renouvelable) ;
- la part d’énergie renouvelable ;
- les émissions GHG Scope 1 (directes), Scope 2 (énergie achetée, lieu et marché) et Scope 3 (chaîne de valeur, avec focus sur les catégories significatives) ghp protocol;
- les cibles de réduction et le plan de transition aligné sur l’Accord de Paris.
Quelques références :
- Directive (UE) 2022/2464 : https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX:32022L2464
- Delegated Regulation (EU) 2023/2772 et ESRS E1 : https://www.efrag.org/sites/default/files/media/document/2024-08/ESRS%20E1%20Delegated-act-2023-5303-annex-1_en.pdf (texte consolidé EFRAG)
AI Act – Transparence énergétique des GPAI
L’AI Act exige des fournisseurs de modèles à usage général (GPAI) :
- un breakdown de la consommation énergétique (entraînement vs inférence) ;
- une documentation technique standardisée (Model Documentation Form) incluant compute, énergie, datasets, etc.
Si les données exactes manquent, des estimations raisonnables basées sur les ressources de calcul sont acceptées. L’AI Office peut exiger des preuves supplémentaires. Le Code of Practice GPAI sert de guide volontaire pour démontrer la conformité.
Pour les modèles mis sur le marché avant le 2 août 2025, une grace period s’applique jusqu’au 2 août 2027 (deux ans). Les obligations deviennent pleinement opposables à partir d’août 2026 pour les amendes sur les GPAI.
Le paradoxe de l’investissement vert et la prime de confiance
94 % des entreprises augmentent leurs budgets IA, mais seulement 12 % des CEO déclarent un bénéfice net visible à ce stade. Le coût de l'énergie est a intégrer dans la perte de ROI.
La consommation électrique des data centers pourrait tripler d’ici 2035 aux États-Unis (de 4 GW en 2024 à 123 GW pour l’IA seule), avec l’IA comme driver majeur ; la gestion active des émissions est impérative. Globalement, les data centers pourraient consommer ~536 TWh en 2025, doublant à ~1 065 TWh d’ici 2030. (deloitte )
Selon PwC, l’IA est un levier central pour le net-zero, mais son empreinte écologique doit être maîtrisée via le carbon-aware scheduling, l’optimisation des workloads et la priorisation des use cases à haute valeur. L’efficacité énergétique croissante de l’IA risque paradoxalement d’accélérer son usage et donc ses impacts (émissions, eau, prix énergie), mais les entreprises peuvent limiter cela en n’autorisant les tokens IA que pour des usages à forte valeur et en planifiant les tâches sur des périodes à faible intensité carbone.
Par ailleurs, les appels d’offres publics et privés intègrent désormais des scores d’efficience énergétique. Cela peut offrir une réduction du coût du capital (réserves de risque allégées), meilleure assurabilité climatique, attractivité investisseurs ESG.
Dans les articles précédents, nous parlions du Risk-Value Score, une métrique conceptuelle utilisée pour évaluer et arbitrer la valeur nette économique d’un projet ou d’un système IA, pénalisée par le coût de la preuve de conformité, les risques réglementaires, assurantiels et opérationnels. Ici on pourrait imaginer une autre pénalisation de ce score en intégrant le coût carbone : valeur nette après conformité énergétique et passif Scope 3.
La réalité énergétique de l’inférence (LLM)
Quand on utilise un LLM, la partie qui consomme le plus d’énergie n’est pas l’entraînement initial du modèle, mais l’inférence : c’est-à-dire le moment où le modèle lit votre question et génère une réponse. Dans les usages réels en production, l’inférence représente 70 à 90 % de toute l’énergie consommée pendant tout le cycle de vie du modèle, alors que l’entraînement initial ne représente plus que 10 à 30 %.(un modèle est entraîné une seule fois ,ou très rarement, mais il répond à des millions, voire des milliards de requêtes par jour).
L’inférence se divise en deux étapes principales :
- Le prefill (phase de préparation) : le modèle lit et traite tout votre message d’entrée en une seule passe parallèle. Ça coûte cher en calcul, surtout si votre question est longue, car l’attention du Transformer est quadratique (plus il y a de mots, plus ça explose).
- Le decoding (phase de génération) : ensuite, le modèle produit les mots un par un (autoregressif). C’est ici que se passe la majorité du travail et de la consommation d’énergie.
Le problème clé : une entrée (prompt) très longue rend le decoding beaucoup plus coûteux par mot généré, parce que le modèle doit relire et réutiliser tout le contexte à chaque nouveau token. Ici, le coût énergétique par token utile peut augmenter fortement. C’est pourquoi il existe des zones optimales : les longueurs d’entrée et de sortie qui consomment le moins d’énergie par token produit. En général, des entrées courtes à moyennes + des réponses de longueur moyenne donnent le meilleur rendement énergétique ; des prompts trop longs ou des réponses trop courtes/courtes font exploser la consommation.
Les chercheurs ont identifié des techniques concrètes qui donnent de vrais gains sans perdre en qualité :
-
Babbling suppression (supprimer le « blabla » inutile) : certains modèles génèrent trop de texte superflu (répétitions, phrases creuses, explications interminables). En bloquant ce comportement, surtout pour générer du code, on économise 44 % à 89 % d’énergie, sans perte de précision. Par exemple, jusqu’à 89 % d’économie sur DeepSeek-6.7B pour des tâches de génération de code.(Towards Green AI: Decoding the Energy of LLM Inference in Software Development)
-
Early-exit (sortie anticipée) : avec des frameworks comme GREEN-CODE, le modèle arrête de calculer les couches inutiles dès qu’il est suffisamment sûr de sa réponse. Ça permet d’économiser 23 % à 50 % d’énergie en moyenne sur des tâches de génération de code, sans dégrader significativement la qualité (Optimizing Energy Efficiency in Large Language Models for Code Generation).
Aujourd’hui, l’inférence est la vraie « pompe à énergie » des LLM. En jouant sur la longueur des prompts/réponses, en coupant le blabla et en sortant plus tôt quand c’est possible, on peut diviser par 2 ou plus la consommation sans sacrifier la performance. C’est un levier énorme pour rendre l’IA plus verte et moins chère à l’échelle industrielle.
Choix radicaux en matériel – L’exemple de Taalas (Canada)
Taalas, une startup canadienne, a choisi une approche vraiment radicale pour accélérer l’IA : au lieu d’exécuter un modèle sur un processeur classique (comme une GPU NVIDIA), ils gravent littéralement le modèle entier – architecture + poids (weights) – directement dans le silicium d’une puce ASIC. C’est comme si on fabriquait un circuit électronique dédié uniquement à un seul modèle d’IA (ici Llama 3.1 8B de Meta), sans passer par un logiciel généraliste.
Les résultats sont impressionnants (mesurés sur du vrai silicium en février 2026) :
- Vitesse : jusqu’à 16 000–17 000 tokens par seconde par utilisateur (pour des entrées/sorties de 1 000 tokens chacune), soit environ 10 fois plus rapide que les meilleures solutions actuelles.
- Comparaison : une NVIDIA H200 fait environ 230 tokens/s sur le même modèle ; Cerebras (déjà très rapide) tourne autour de 1 900–2 000 tokens/s ; Groq, SambaNova et autres sont en dessous.
- Coût : l’inférence coûte 10 à 20 fois moins cher à produire et à faire tourner.
- Consommation électrique : 10 fois moins d’énergie qu’une implémentation logicielle classique.
- Densité : la puce unifie calcul et mémoire sur une seule puce à une densité proche de celle de la DRAM (mémoire vive classique), ce qui élimine complètement le fameux « mur compute-mémoire » (le goulot d’étranglement où les données doivent voyager entre la mémoire et le processeur, ce qui ralentit et consomme énormément sur les GPU).
Le gros inconvénient est qu'une fois le modèle gravé dans le silicium, la puce n’est plus programmable. Cette approche est donc réservée à des usages très spécifiques et à très gros volume, comme :
- des chatbots 24/7 ultra-fréquents,
- des services d’inférence massive (millions d’utilisateurs simultanés),
- des agents autonomes qui doivent répondre en quasi-instantané à très bas coût.
En clair : Taalas sacrifie la flexibilité pour atteindre une efficacité extrême sur un seul modèle populaire. C’est une rupture totale avec les GPU polyvalents de NVIDIA : au lieu d’un outil général qui fait tout (mais lentement et cher), on a un outil ultra-spécialisé qui fait une seule chose… mais incroyablement vite, pas cher et avec très peu d’énergie. Le "hardwiring" de Taalas offre un énorme avantage pour l'embarquabilité sur des workloads spécifiques, à haute volumétrie et temps réel, où on priorise vitesse, faible consommation et faible coût plutôt que la flexibilité.
Référence :
- Article officiel Taalas (février 2026) : https://taalas.com/the-path-to-ubiquitous-ai
- Forbes (février 2026) : https://www.forbes.com/sites/karlfreund/2026/02/19/taalas-launches-hardcore-chip-with-insane-ai-inference-performance
L’efficience cognitive : un nouvel attribut de l’IA industrialisée
En plus de sa précision ou sa vitesse, L'IA sur juge sur son rendement cognitif : la valeur réelle produite par unité d’énergie (kWh ou token par watt-heure). Un modèle brillant mais énergivore devient un passif financier, un risque CSRD et un frein à la scalabilité des agents autonomes. Ce septième volet prolonge la maîtrise runtime : après borner les actions, il faut borner leur coût énergétique de façon opposable et continue. L’efficience cognitive est une propriété au runtime contribuant à la viabilité économique et réglementaire dans une Europe carbone-consciente. Les projections IEA sont claires : 415 TWh pour les data centers en 2024 (1,5 % mondial), doublant à ~945 TWh en 2030, avec l’IA comme moteur principal. Ce basculement redéfinit la valeur : le ratio valeur/kWh s'ajoute, aux côtés de la précision et de la vitesse. Intégrer cet attribut au runtime – budgets énergétiques, carbon-intensity checks, overrides automatiques – offre une avance concurrentielle, juridique et sociale pour déployer l’IA à haute valeur ajoutée sans heurter les murs réglementaires ni physiques.
Lego II - RegOS - Sac 7
Les opinions exprimées dans cet article sont strictement personnelles et ne reflètent pas nécessairement celles de mon employeur. Les contenus sont fournis à titre informatif et ne constituent pas un conseil juridique. Cet article explore des concepts architecturaux émergents et analyse des tendances de marché. RegOS est ici une proposition conceptuelle personnelle et non propriétaire — un cadre d'ingénierie systémique que j'explore pour contribuer au débat public sur la conformité IA industrialisée en Europe.