La Donnée comme Actif Stratégique

Les deux premiers volets de cette série ont volontairement déplacé le débat sur l’IA hors du champ habituel de la performance algorithmique.
Dans Architecture du Risque, nous avons vu que la conformité IA ne peut plus être traitée comme une activité administrative ou juridique périphérique ; elle doit devenir une fonction système, codifiée au cœur des architectures techniques.
Dans un monde où les systèmes IA sont non déterministes, évolutifs et interconnectés, l’absence de gouvernance intégrée transforme l’innovation en passif latent : passif juridique, passif cyber, passif réputationnel, et in fine passif financier.
Le second volet, La Forge de Confiance, a montré comment cette fonction système pouvait être rendue exécutable industriellement : pipelines bloquants, Policy-as-Code, SBOM, monitoring post-marché, DPIA vivants, et surtout l’introduction d’un Risk-Value Score (RVS) permettant d’arbitrer rationnellement entre valeur attendue et coût de la preuve .
Si la conformité devient une fonction système, et si cette fonction est industrialisée via une forge, alors une question s’impose naturellement : quel est l’actif économique réellement protégé, amplifié et monétisable par cette architecture ? C’est la donnée. Elle est le seul élément :
- transversal à tous les régimes réglementaires,
- présent sur toute la chaîne de valeur (collecte → transformation → exploitation → assurance),
- et directement corrélé à la création de valeur business durable.
C’est précisément pour cette raison que toutes les grandes réglementations européennes convergent vers la donnée, même lorsqu’elles ne la nomment pas explicitement.
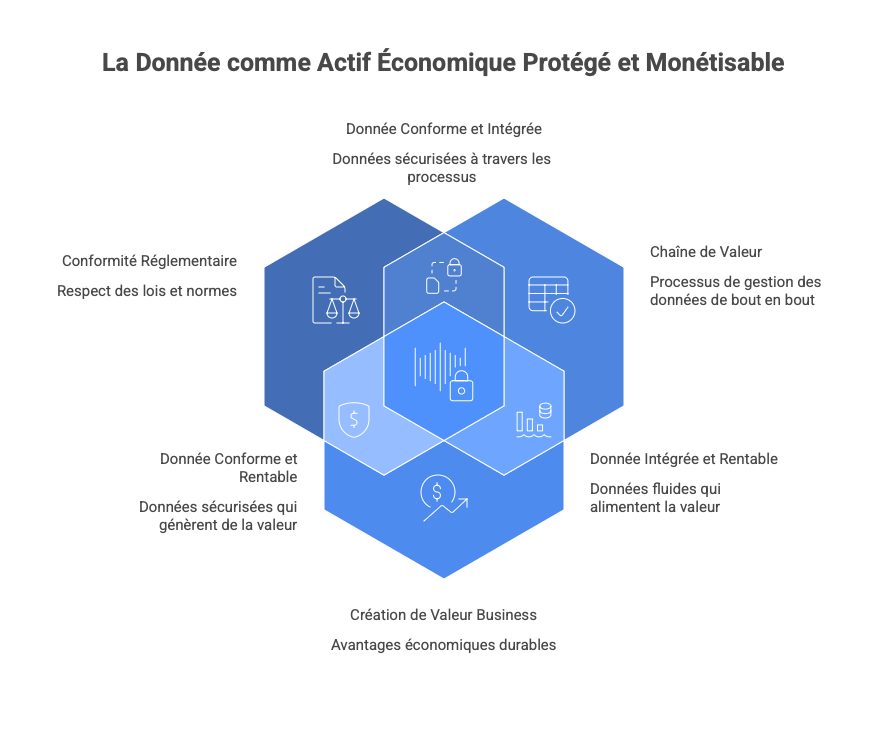
Le RegOS, tel que défini dans les deux premiers articles, n’est pas un outil de conformité. C’est une infrastructure de décision économique sous contrainte réglementaire, s'il permet d’arbitrer les projets IA, alors la donnée devient l’élément central de cet arbitrage:
- le coût de la preuve porte d’abord sur la donnée,
- le RGPD conditionne sa licéité exploitable,
- l’AI Act conditionne son utilisabilité algorithmique,
- NIS2 conditionne sa disponibilité et son intégrité,
- DORA conditionne sa continuité opérationnelle,
- le CRA conditionne sa sécurité logicielle,
- les DPIA conditionnent sa soutenabilité juridique dans le temps.
- la majorité des sanctions, incidents et disqualifications marché sont liés à des défaillances data,
- et la valeur économique (assurance, confiance, accès marché) se concentre sur la gouvernance data.
Autrement dit, la donnée n’a de valeur que si elle reste exploitable sous stress réglementaire.
C’est exactement ce que permet le RegOS :
- transformer des obligations abstraites en contraintes exécutables,
- rendre la gouvernance data mesurable,
- et convertir la conformité en barrière à l’entrée.
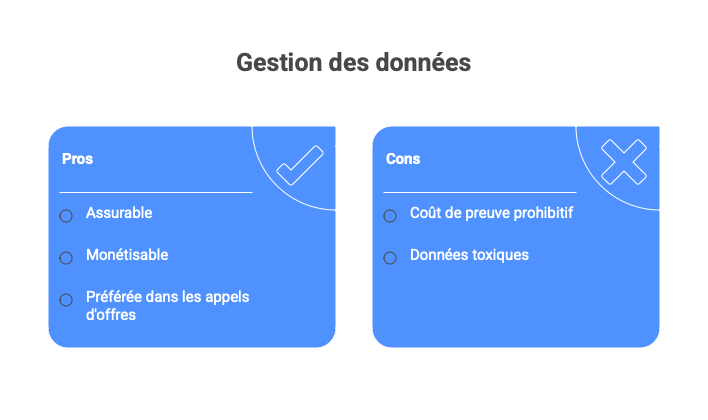
Le Risk-Value Score, appliqué à la donnée permet de comparer deux jeux de données non pas sur leur volume ou leur richesse, mais sur leur capacité à générer de la valeur nette après conformité, assurance et exploitation.
Une donnée peut être :
- techniquement riche,
- mais économiquement toxique si son coût de preuve est prohibitif.
À l’inverse, une donnée bien gouvernée, bien cloisonnée et bien documentée devient :
- assurable,
- monétisable,
- et préférée dans les appels d’offres.
La donnée comme actif stratégique dans un paysage réglementaire multiple
Dans l’économie numérique actuelle, la donnée ne se réduit plus à un simple input technologique : elle constitue un actif stratégique, commercial et juridique. Les entreprises qui réussissent aujourd’hui sont celles qui parviennent à transformer cet actif en valeur business tout en respectant un ensemble complexe de cadres réglementaires européens et internationaux.
Il est essentiel de comprendre la gouvernance de la donnée comme un écosystème de normes, chacune interagissant avec les autres, imposant des obligations, des risques mais aussi des opportunités.
Donnée et business : de la dette réglementaire à la valeur stratégique
Si la nouvelle régulation comporte un coût et une lourdeur administrative, une lecture exclusivement compliance-centrée est trop étroite. Aujourd’hui, les cabinets d’analyse convergent vers un paradigme plus puissant : la donnée est un actif stratégique conditionné par la gouvernance.
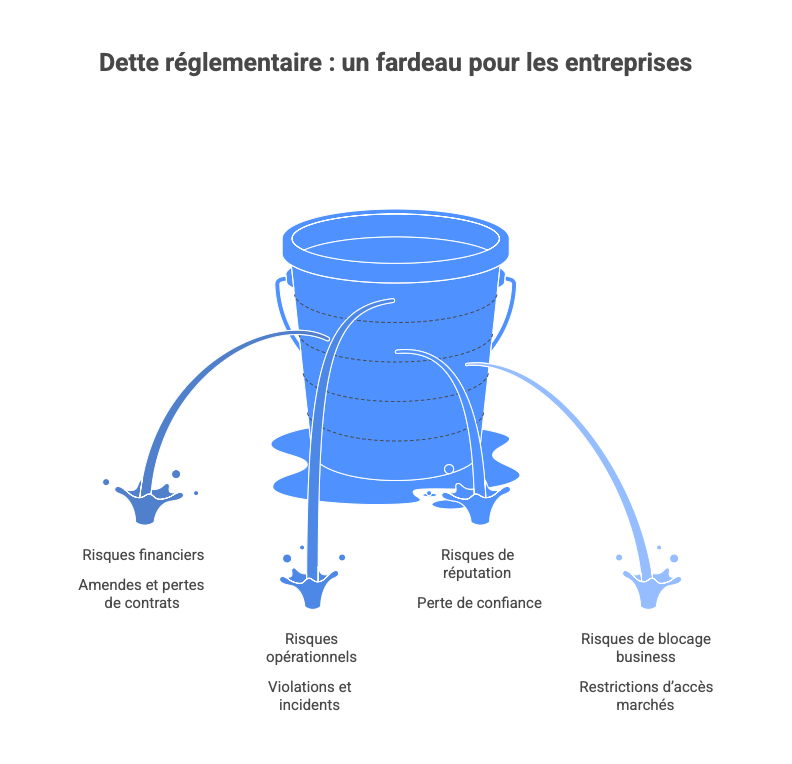
Par ailleurs, une donnée non gouvernée génère ce qu’on peut appeler une "dette réglementaire", qui se manifeste par :
- risques financiers (amendes, pertes de contrats),
- risques opérationnels (violations, incidents),
- risques de réputation (perte de confiance),
- risques de blocage business (restrictions d’accès marchés, refus de certifications).
Contrairement à une vision purement punitive, cette dette se transforme en actif valorisable lorsque l’entreprise :
- Intègre une gouvernance data robuste, compliant aux cadres multiples cités plus haut.
- Produit des preuves de conformité et de maîtrise.
- Transforme ce positionnement en avantage commercial et financier.
Un moat se construit autour de la capacité d’un acteur à protéger et valoriser ses données dans un contexte réglementaire exigeant. Ce moat diffère selon les secteurs:
Dans l'industrie & Manufacturing la donnée se répartit entre systèmes opérationnels et systèmes informatiques. Les réglementations comme NIS2 imposent une sécurité accrue pour les infrastructures critiques. Ici, une architecture data qui intègre automatiquement les exigences de sécurité et de conformité facilite la continuité des services et devient un critère d’éligibilité aux appels d’offres gouvernementaux.
Le secteur de la santé gère des données hautement sensibles. La combinaison RGPD + AI Act + DPIA fait de la gestion de données un prérequis absolu pour toute solution IA. Pour les organisations qui démontrent une maîtrise complète de leurs données (traçabilité, consentement, auditabilité) il y a un accroissement de leur acceptation réglementaire et une réduction des risques d’incidents; elles augmentent la confiance des patients et partenaires.
Le secteur de l’énergie s’appuie sur des réseaux critiques. La conformité NIS2 + auditabilité des flux favorise la résilience; disposer d'une capacité à prouver des trajectoires de reprise et de continuité, permet des partenariats long terme et des contrats à haute valeur.
Le secteur de la finance est soumise à DORA, qui exige des mesures strictes de résilience numérique. C'est ici que les institutions capables de démontrer une maîtrise complète de leur gouvernance des données critiques bénéficient d’une meilleure notation de risque opérationnel et d’un coût du capital réduit.
Nous voyons ici que la donnée est un actif à risque, et les assureurs l'on bien compris. Alors que la régulation se complexifie, les marchés assurantiels se transforment : les assureurs développent des couvertures spécifiques autour du risque data (failles, non-conformité RGPD/AI Act, interruption, breaches, exfiltration).
Les critères d’assurance incluent désormais la traçabilité, la qualité, la documentation, la gouvernance et la résilience des données, car une maturité data faible augmente l'exposition et peut rendre le risque non assurable ou entraîner des primes prohibitivement élevées.
Exemples :
- L’EIOPA expose, dans son Opinion on Artificial Intelligence governance and risk management (2025), comment les assureurs doivent évaluer et gérer les risques liés aux données dans les systèmes AI, avec un accent fort sur la data governance (qualité, complétude, documentation, prévention des biais) comme pilier pour une utilisation responsable et pour réduire les risques opérationnels/cyber. eiopa
- Chez Lloyd’s, les Minimum Standards MS11 – Cyber Resilience and Data Management imposent un cadre de data governance robuste, incluant qualité des données, procédures d'escalade et revue régulière, ce qui influence directement la souscription cyber et les primes (une maturité data élevée réduit les expositions et favorise des couvertures plus larges/moins chères) assets-lloyds
L'assurance de la data est un pan économique qui devient de plus en plus important s’articulant autour de l’évaluation quantitative du risque data, la réduction des sinistres grâce à la conformité et la fidélisation grâce à des produits intégrés de gestion des risques.
Finalement, dans cet environnement orienté data, un nouveau KPI critique émerge : la prime de confiance qui définit la capacité d’une organisation à fournir des preuves objectivables de gouvernance et de maîtrise de ses données.
Cette prime se matérialise dans :
- les contrats publics (critères d’éligibilité renforcés),
- les partenariats B2B (exigences clauses data),
- les relations investisseurs (transparence et réduction du risque réglementaire),
- l’assurabilité (notes de risque, primes réduites).
Dans un marché où les exigences de conformité s’accroissent (par exemple, obligations de preuve face à des injonctions extraterritoriales), cette prime devient désormais un élément de compétitivité.
La gouvernance des données n’est plus un sujet purement technique ou juridique. Elle constitue un pivot stratégique de compétitivité et de création de valeur. L’intégration simultanée des cadres RGPD, AI Act, NIS2, DORA, CRA, DPIA et des risques extraterritoriaux devient un levier business, permettant aux organisations de maximiser le ROI des projets IA, de réduire les risques opérationnels et financiers, d'augmenter leur prime de confiance, et construire des moats durables dans leurs secteurs.
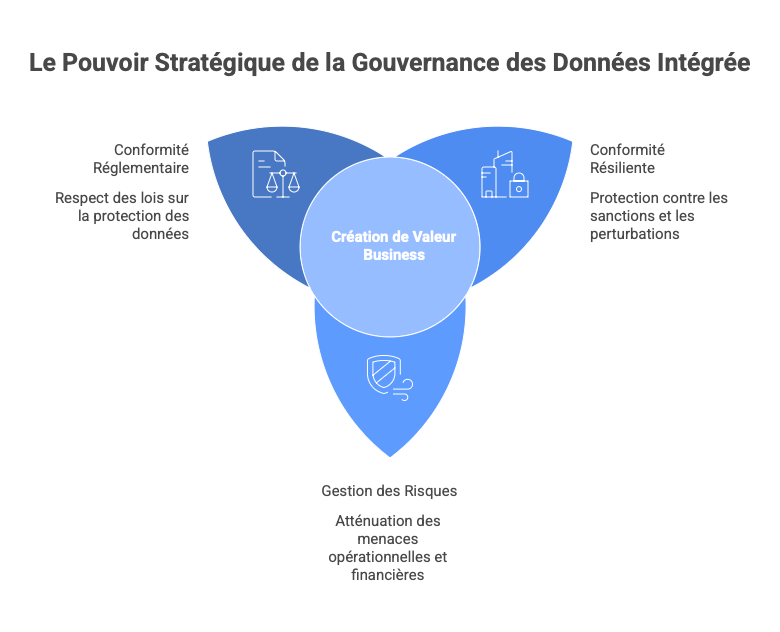
Le RegOS comme "pare-feu" juridique et informationnel au runtime
Dans les architectures IA contemporaines, le risque ne provient plus uniquement de la décision algorithmique, mais de la circulation de l’information à travers l’ensemble du système : collecte, transformation, apprentissage, inférence, exposition via API, et persistance implicite dans les poids des modèles.
C’est précisément à ce niveau que la majorité des stratégies de conformité échouent aujourd’hui : elles raisonnent en termes de documents, de processus déclaratifs ou de contrôles a posteriori, alors que le droit européen impose une maîtrise comportementale continue.
Dans ce contexte, le RegOS ne peut pas être conçu comme une couche de reporting ou de gouvernance abstraite. Il doit agir comme un pare-feu juridique et informationnel runtime, capable de :
- limiter structurellement ce qu’un système peut apprendre,
- contrôler ce qu’il peut restituer,
- empêcher ce qu’il ne doit jamais exposer,
- et produire, en continu, des preuves techniques opposables.
Cette exigence découle directement du déplacement du droit : on ne juge plus seulement l’intention ou la conception, mais l’état réel du système en fonctionnement, comme l’imposent explicitement le post-market monitoring de l’AI Act et la logique de state of the art security du RGPD et de NIS2 .
Anonymisation : la fin des illusions statistiques
L’un des angles morts les plus dangereux des projets IA industriels reste la confusion persistante entre anonymisation et pseudonymisation.
Le RGPD est pourtant explicite : une donnée n’est considérée comme anonymisée que si la ré-identification est raisonnablement impossible, compte tenu des moyens techniques actuels et futurs. Or, dans les systèmes IA modernes, cette condition est de plus en plus difficile à satisfaire.
Les travaux académiques et les positions des autorités européennes convergent sur un point : la majorité des jeux de données prétendument "anonymisés" ne le sont pas.
Les risques ne sont pas seulement théoriques — ils sont reconnus et documentés par les autorités européennes de protection des données dans leurs travaux récents sur l’IA et la protection des données personnelles. Parmi les vulnérabilités identifiées :
- Ré-identification par recoupement ou “linkage attacks”, lorsque des données apparemment anonymisées peuvent être reconstruites en combinant plusieurs sources.
- Membership inference, où un attaquant peut déterminer si une donnée particulière a servi à l’entraînement d’un modèle.
- Model inversion, conduisant à la reconstruction partielle d’attributs sensibles à partir de sorties de modèle.
- Extraction de données mémorisées dans les poids des modèles, un risque accru par l’apprentissage profond et la sur-mémorisation.
Ces catégories d’attaque sont explicitement mentionnées dans les documents techniques de l’European Data Protection Board (EDPB) sur les risques de confidentialité liés aux LLMs, qui exigent que les risques de ré-identification, de membership inference et de model inversion soient mesurés et contrôlés dans des limites strictes (< 1 % de succès acceptable uniquement après tests internes et audits externes pour les données sensibles) (EDPB).
De plus, l’EDPB a publié l’Opinion 28/2024 sur les aspects de protection des données liées au traitement de données à caractère personnel dans le contexte des modèles d’IA, dans laquelle il souligne que les modèles entraînés avec des données personnelles ne peuvent pas être considérés comme anonymes par défaut, et que il faut évaluer rigoureusement si une extraction ou une ré-identification est possible pour apprécier la conformité au RGPD (EDPB).
Les lignes directrices du European Data Protection Supervisor (EDPS) en matière d’IA générative et de gestion des risques soulignent, quant à elles, la nécessité de stratégies robustes de gestion des risques pour protéger les droits fondamentaux, ce qui inclut la prise en compte des vecteurs d’attaque tels que l’inversion ou l’extraction de données sensibles par les systèmes d’IA (edps.europa.eu).
Dans un RegOS mature, l’anonymisation ne peut donc pas être une étape ponctuelle en amont ou un simple masquage syntaxique.
Elle doit devenir une propriété systémique, combinant plusieurs couches :
- Minimisation stricte,
- Suppression structurelle des quasi-identifiants,
- Differential Privacy, appliquée non seulement aux outputs mais aussi aux gradients et aux métriques (arxiv1, arxiv2)
- Segmentation des usages : une donnée peut être légale pour l’analytics mais interdite pour l’apprentissage,
- Preuve d’efficacité de l’anonymisation, documentée et réévaluable.
Le RegOS doit être capable de démontrer que la valeur économique extraite d’un dataset ne dépend plus de la possibilité d’identifier un individu, condition sine qua non de sa soutenabilité juridique.
Sécurisation de la donnée : de la cyber-sécurité à l’anti-theft informationnel
La sécurisation de la donnée dans les architectures IA ne peut plus se limiter aux paradigmes classiques de la cybersécurité (confidentialité, intégrité, disponibilité).
Les régulations récentes — NIS2, CRA, mais aussi le Data Act — imposent une responsabilité directe sur les flux, y compris :
- APIs,
- pipelines ML,
- services d’inférence,
- systèmes edge et IoT.
Or, les incidents récents montrent que l’exfiltration de données ne passe plus par des bases compromises, mais par :
- des APIs trop permissives,
- des modèles interrogés de manière malveillante,
- des mécanismes d’authentification faibles,
- ou des chaînes de dépendances non maîtrisées.
Dans les architectures IA, la donnée n’est plus seulement menacée par des attaques frontales ou des compromissions massives. Le risque dominant est désormais l’exfiltration progressive, indirecte et légalement invisible, opérée à travers des usages légitimes en apparence : APIs, requêtes d’inférence, appels automatisés, ou interactions agentiques.
Contrairement aux systèmes d’information traditionnels, où le vol de données implique généralement une rupture de sécurité explicite, les systèmes IA permettent une fuite informationnelle sans violation apparente. Un attaquant peut rester authentifié, autorisé, et conforme en surface, tout en reconstruisant progressivement des informations sensibles.
C’est pour répondre à cette menace spécifique que le RegOS doit intégrer une logique d’anti-thefting informationnel, complémentaire mais distincte de la cybersécurité classique :
Zero Trust strict : ne jamais faire confiance au contexte, seulement à l’identité
Le premier pilier de l’anti-thefting informationnel est l’application stricte du paradigme Zero Trust, non seulement aux utilisateurs humains, mais aussi aux services, agents et workloads IA.
Dans un RegOS mature aucun composant n’est implicitement digne de confiance, même s’il se trouve dans le même réseau ou le même cluster. Chaque appel entre services (ingestion, entraînement, inférence, supervision) est authentifié, chiffré, et autorisé explicitement.
Cela se traduit techniquement par :
- mTLS (mutual TLS) pour garantir l’authenticité réciproque des services,
- identités de workload (NHI) pour lier chaque action à un composant précis,
- des politiques d’accès minimales, dynamiques et révocables.
le RegOS agit comme autorité centrale d’identité et de politique, capable de bloquer un flux même s’il est techniquement valide, dès lors qu’il viole une contrainte réglementaire ou informationnelle.
Limitation sémantique des requêtes : contrôler ce que l’on peut demander à un modèle
La majorité des fuites de données via les modèles ne proviennent pas d’un accès non autorisé, mais d’interrogations intelligentes.
Un modèle peut être juridiquement conforme dans sa conception, tout en permettant — via une succession de requêtes — de révéler des informations sensibles, reconstruire des profils, ou extraire des fragments mémorisés.
La limitation sémantique des requêtes consiste à contrôler le sens et l’intention informationnelle des demandes adressées au modèle, et pas uniquement leur format ou leur volume.
Rate-limiting contextuel : limiter la fuite d’information, pas seulement le trafic
Le rate-limiting classique repose sur une logique volumétrique : nombre de requêtes par seconde, bande passante, CPU.
Or, dans les systèmes IA, le volume n’est pas un bon proxy du risque. Une exfiltration efficace peut se produire via peu de requêtes, lentement, chacune prise isolément parfaitement légitime.
Le RegOS doit donc mettre en œuvre un rate-limiting informationnel, fondé sur :
- la quantité d’information nouvelle produite,
- la sensibilité cumulative des réponses,
- la corrélation entre requêtes successives.
Ici le RegOS agrége l’historique des interactions et décide non pas si une requête est valide, mais si elle est encore acceptable compte tenu de ce qui a déjà été révélé.
Cette logique est essentielle pour satisfaire l’esprit du RGPD (minimisation, limitation de finalité) et du Data Act, qui imposent un contrôle réel de l’usage des données, pas seulement de leur accès.
Détection d’exfiltration lente : identifier la fuite avant qu’elle ne soit visible
L’un des risques les plus sous-estimés est la slow data leakage : une fuite d’information progressive, étalée dans le temps, souvent indétectable par des mécanismes de sécurité classiques.
Dans un RegOS avancé, cela implique : des modèles de détection comportementale
La difficulté est que chaque action est individuellement légitime. Ce n’est que leur combinaison temporelle qui révèle une intention d’exfiltration.
Il s'agit de corréler les signaux faibles, déclencher des alertes graduelles, voire imposer des mécanismes de ralentissement, de bruit ou de blocage adaptatif.
Cette capacité est essentielle pour répondre aux obligations de détection et de réaction imposées par NIS2 et aux exigences de post-market monitoring de l’AI Act.
Journalisation immuable : produire une vérité opposable
Enfin, aucun mécanisme d’anti-thefting informationnel n’a de valeur réglementaire sans preuve. Le RegOS doit donc produire une journalisation immuable, couvrant les requêtes, les décisions de filtrage, les blocages, les alertes et les actions correctives.
Cette approche est cohérente avec les exigences de NIS2 sur la prévention, la détection et la réponse aux incidents, mais aussi avec le CRA, qui rend le fabricant responsable des vulnérabilités exploitables sur toute la durée de vie du produit numérique .
L’exfiltration depuis les modèles : quand l’IA devient un vecteur de fuite
Un point encore trop peu traité dans les stratégies de gouvernance est le fait que les modèles eux-mêmes deviennent des vecteurs d’exfiltration.
Contrairement à une base de données classique, un modèle :
- mémorise de manière diffuse,
- restitue de manière probabiliste,
- et peut être interrogé de façon adaptative.
Cela rend possibles :
- l’extraction de données d’entraînement,
- la reconstruction de patterns sensibles,
- la fuite indirecte de secrets industriels ou de données personnelles.
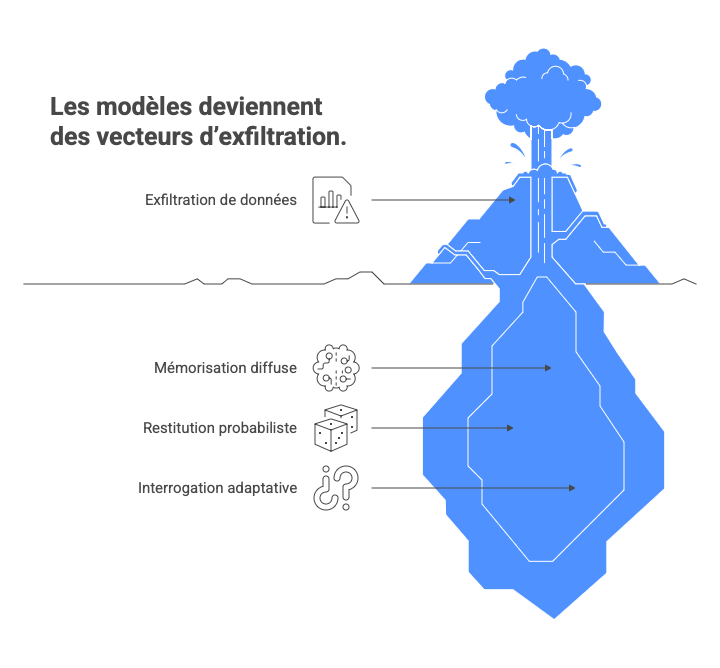
Ces risques sont désormais reconnus par les régulateurs et par les frameworks comme l’OWASP Top 10 for LLM Applications.
Dans un RegOS industriel, cela implique :
- Tests systématiques d’extraction et d’inversion avant mise en production,
- Guardrails runtime sur les sorties,
- Séparation stricte des contextes (RAG cloisonné),
- Chiffrement des embeddings sensibles,
- Kill-switch réglementaire en cas de comportement déviant.
L’IA n’est plus considérée comme un simple composant fonctionnel, mais comme un acteur informationnel à risque, au même titre qu’un service exposé sur Internet.
Intégrer toutes les réglementations : le RegOS comme méta-système
Enfin, le point le plus critique : aucune réglementation ne peut être traitée isolément.
Le RGPD, l’AI Act, le Data Act, NIS2, DORA, CRA ne sont pas des silos. Ils forment un système normatif cohérent mais exigeant, centré sur la donnée.
Le RegOS est précisément ce méta-système capable de traduire des obligations juridiques en contraintes techniques, d'arbitrer les conflits, de produire des preuves continues, et de maintenir la viabilité économique.
Sans cette couche systémique, la conformité devient une accumulation de dettes incompatibles.
Conclusion
La donnée n’est plus un carburant gratuit. Elle est un actif conditionnel, dont la valeur dépend de sa gouvernance sous contrainte.
Le RegOS n’est pas un luxe architectural. C’est une réponse crédible à un monde où : les modèles sont faillibles, les benchmarks sont trompeurs, les données fuient, et la régulation s’exécute.
Ceux qui comprennent cela ne construisent pas simplement des IA conformes. Ils construisent des actifs industriels durables, assurables, monétisables et préférés.
*Lego II - RegOS - Sac 3
Les opinions exprimées dans cet article sont strictement personnelles et ne reflètent pas nécessairement celles de mon employeur. Les contenus sont fournis à titre informatif et ne constituent pas un conseil juridique. Cet article explore des concepts architecturaux émergents et analyse des tendances de marché. RegOS est ici une proposition conceptuelle personnelle et non propriétaire — un cadre d'ingénierie systémique que j'explore pour contribuer au débat public sur la conformité IA industrialisée en Europe.